
Windows 10系统编程——Chapter 1笔记
Windows架构总览
这本《Windows 10 System Programming》还真是从0开始教起。为了让我们更好的理解Windows的架构,我们还是需要从一些基本的起步进行说明
进程
A process is a containment and management object that represents a running instance of a program.
进程是一个正在活动的程序实体,进程也为我们的程序分配真正的内存,CPU和其他运行时的资源。这就是进程。换而言之——活着的程序。这也是为什么我们需要说明一个程序到底包含什么。
Windows的进程会稍微比Linux的进程要复杂一些。它实际上包含如下的一些内容。
- 可执行程序,包含用于在进程内执行代码的初始代码和数据。这就是上面我们提到的定义的Program
- 私有虚拟地址空间,用于为进程内代码所需的任何目的分配内存。这实际上说明的就是我们的内存资源。
- 访问令牌(有时称为主令牌),它是一个存储进程默认安全上下文的对象,供在进程内执行代码的线程使用(除非线程通过使用模拟来获取其他令牌)。
- 执行体(内核)对象(例如事件、信号量和文件)的私有句柄表。
- 一个或多个执行线程。普通的用户模式进程由一个线程创建,(执行进程的主入口点)。没有线程的用户模式进程,几乎毫无用处,在正常情况下会被内核销毁。(就像没有人干活的进程。。。嗯,僵尸进程?)
DLL动态链接库
我们将那些可以被重定位的代码,资源,数据和文件集合起来,成为一个可以被动态放到进程地址空间的(说白了就是可以扔到进程中被进程访问到的)程序合集成为动态库。这些动态库在进程被拉起,或者是我们需要的时候,加载进入线程让CPU对代码进行执行。
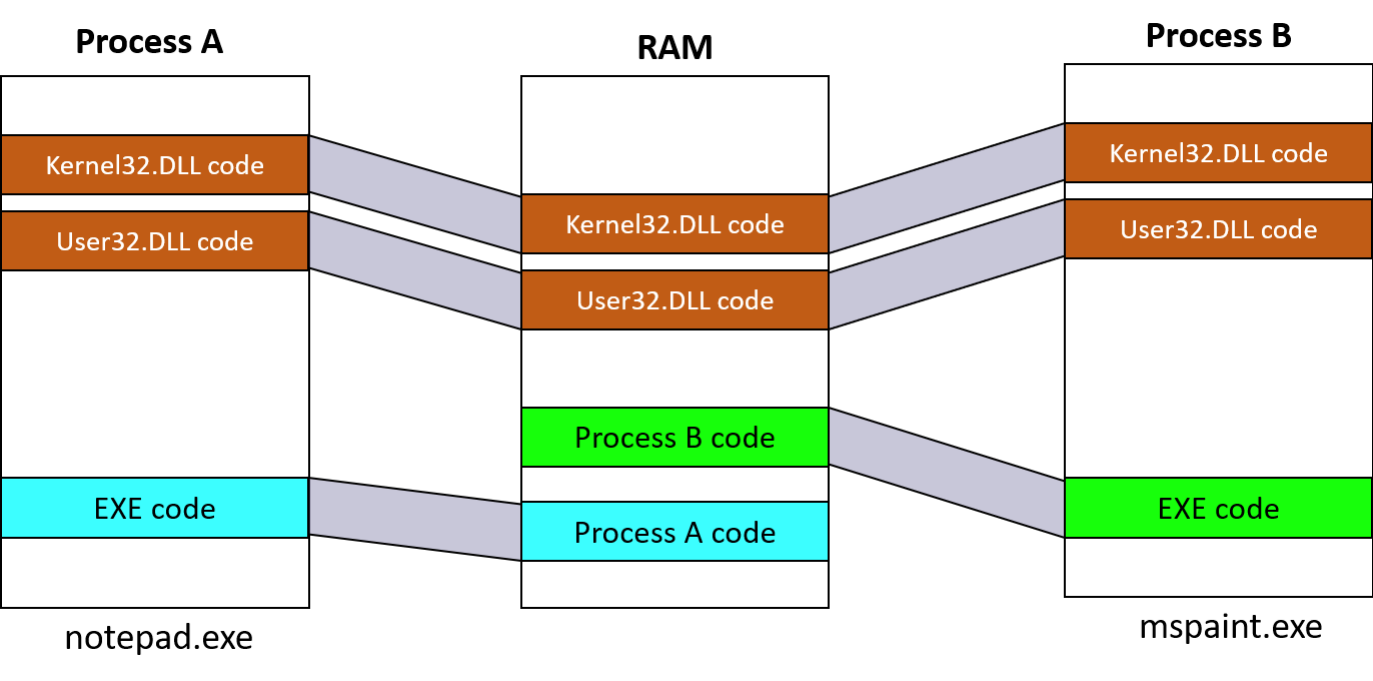
我们可以用这个图来建立一个进程样式的全貌。这里先放到这里我们参考
虚拟内存
咱们的每一个进程都是有虚拟内存的,看起来,我们的进程好像霸占了所有的地址空间。每个进程都有其自己的虚拟、私有、线性地址空间。该地址空间初始为空(或接近于空,因为可执行映像和 NtDll.Dll 通常最先被映射)。一旦主线程(第一个线程)开始执行,就可能会分配内存、加载更多 DLL 等等。该地址空间是私有的,这意味着其他进程无法直接访问它。地址空间范围从零开始(尽管从技术上讲,前 64KB 地址无法分配),一直到最大值,最大值取决于进程的“位数”(32 位或 64 位)、操作系统的“位数”以及链接器标志。
对于32位的Windows,给咱们用户的地址空间大小也就是2GB,我们当然可以后面调整到跟Linux类似的3:1模型,但是需要我们自己额外的进行设置。
对于64位的Windows,地址空间大小为 8 TB(Windows 8 及更早版本)或 128 TB(Windows 8.1 及更高版本)。这个我们也可以进行设置,也就是上一个LARGEADDRESSAWARE的FLAG。
虚拟内存虚拟在——我们实际上压根没有直接操作RAM,而是使用一些机制将我们的操作做映射。这里是基础,不详细展开讨论咱们的Windows到底在做什么。
线程
实际执行代码的实体是线程。线程包含在进程中,使用进程公开的资源(例如虚拟内存和内核对象句柄)来执行工作。我们现在思考一下,作为一个执行流的线程,要有什么?
- 当前访问模式:用户或内核。
- 处理器的执行上下文,比如说寄存器的一些值,处理器特殊flags的一些cache
- 线程的堆栈,这些是用来存储局部变量分配和调用管理。
- 线程本地存储 (TLS) 数组,提供一种以统一访问语义存储线程私有数据的方法。
- 基本优先级和当前(动态)优先级。
- 处理器亲和性,指示允许线程在哪些处理器上运行。。
好像怎么也逃不了的一些组件名称
下面这些概念挺常见的,我这里整理了一下,放在这里。
-
用户进程 (User Processes)
这些是你在电脑上日常使用的应用程序,比如 Notepad.exe、cmd.exe 和 explorer.exe。它们都是基于可执行文件(映像文件)启动的普通程序。
-
服务进程 (Service Processes)
服务进程是特殊的 Windows 进程,由服务控制管理器 (SCM)(位于 services.exe 中)管理。SCM 可以启动、停止、暂停或恢复这些服务,并发送其他指令。
-
系统进程 (System Processes)
这是一类总称,指那些通常在后台默默运行、对系统正常运行至关重要的进程。有些是“原生进程”,只使用 Windows 原生 API。如果终止其中一些进程(如 Smss.exe、Lsass.exe 和 Winlogon.exe),可能会导致系统崩溃。
-
子系统进程 (Subsystem Processes)
Windows 子系统进程(通常是 Csrss.exe)是内核的“助手”,负责管理 Windows 进程。它是一个关键进程,如果被终止,系统也会崩溃。通常每个用户会话都会有一个实例。
-
子系统 DLL (Subsystem DLLs)
这些是实现子系统 API 的动态链接库(DLL)。它们为用户进程提供与操作系统交互的接口。著名的例子包括 kernel32.dll、user32.dll 和 gdi32.dll。这些 DLL 主要包含官方文档中公开的 Windows API。
-
NTDLL.DLL
这是一个低层的系统级 DLL,实现了 Windows 原生 API。尽管它仍在用户模式下运行,但其最重要的功能是执行系统调用,将控制权从用户模式转移到内核模式。它还实现了堆管理器和映像加载器等核心功能。
-
内核 (Kernel)
这是操作系统最底层、最关键的部分。它负责处理核心任务,如线程调度、中断和异常处理,以及实现基本的同步原语(如互斥锁和信号量)。为了提高效率,部分代码甚至使用汇编语言编写。
-
执行程序 (Executive)
执行程序是内核的上一层,包含了大部分内核模式代码。它像一个“管理器集合”,托管着各种管理器,比如对象管理器、内存管理器、I/O管理器和即插即用管理器等。它比内核层大得多。
-
Win32k.sys
这是 Windows 子系统的内核模式部分,是一个驱动程序。它负责处理所有的窗口操作和图形设备接口(GDI)API,这意味着所有用户界面相关的操作都由它管理。
-
设备驱动程序 (Device Drivers)
设备驱动程序是可加载的内核模块。它们在内核模式下执行,可以完全访问内核功能。经典的驱动程序在硬件和操作系统之间提供连接,而其他类型的驱动程序则提供过滤功能。
-
硬件抽象层 (Hardware Abstraction Layer, HAL)
HAL 位于最靠近硬件的层面,为设备驱动程序提供了一个抽象接口。它允许驱动程序使用统一的 API,而无需了解底层硬件(如中断控制器或 DMA 控制器)的复杂细节。
-
Hyper-V 虚拟机管理程序 (Hyper-V Hypervisor)
在支持虚拟化安全(VBS)的系统上,Hyper-V 虚拟机管理程序会存在。VBS 是一项额外的安全功能,它让操作系统本身运行在一个由 Hyper-V 控制的虚拟机中,从而提供了更高的安全性。
编程初体验
这里share一点不一样的
笔者不太喜欢Visual Studio,感觉还是太大了,咱们这里更多的是玩玩具。如果你不是vsc的忠实用户,可以直接跳过这里,快速的去看您感兴趣的内容。这里说明的是如何在Visual Studio Code下配置环境的办法。
首先,您需要保证您的CMake和cl.exe等编译套包是可以被检索到的,意味着你先前使用过MSVC编译过东西。CMake会自动处理具体的环境变量问题,让我们至少使用起来不用单独跑到VS的Develop Prompt下进行编译。
下一步是设置一下笔者喜欢的C++版本,也就是C++23。笔者后面更多会倾向于使用现代C++而不是C来编程。所以你需要在CppTools的Cpp Standard中设置成C++23,以及笔者喜欢的format是WebKit,这也是之后笔者的代码风格。完事之后,笔者展示一下自己的CMakeLists.txt和测试的文件。
cmake_minimum_required(VERSION 3.10.0)
project(WinSysProgram1 VERSION 0.1.0 LANGUAGES C CXX)
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
set(CMAKE_CXX_STANDARD 23)
add_executable(WinSysProgram1 main.cpp)
#include <Windows.h>
#include <iostream>
#include <print>
int main()
{
// system info
SYSTEM_INFO sysInfo;
::GetNativeSystemInfo(&sysInfo);
std::print("\nWe can dump all the args in sysInfo in one print statement\n");
std::print(" Number of processors: {},\n Page size: {} bytes,\n Processor type: {},\n "
"Allocation granularity: {} bytes,\n Minimum application address: {},\n "
"Maximum application address: {}\n",
sysInfo.dwNumberOfProcessors, sysInfo.dwPageSize, sysInfo.dwProcessorType,
sysInfo.dwAllocationGranularity, sysInfo.lpMinimumApplicationAddress,
sysInfo.lpMaximumApplicationAddress);
std::print(" Active processor mask: {},\n Processor architecture: {},\n "
"Processor level: {},\n Processor revision: {}\n",
sysInfo.dwActiveProcessorMask, sysInfo.wProcessorArchitecture,
sysInfo.wProcessorLevel, sysInfo.wProcessorRevision);
return 0;
}
您可以尝试搭建一个CMake的构建环境,基于MSVC的编译环境,得到结果可以运行一下,注意这个是打印我们系统的相关信息,因此,每个人的都会不一样
We can dump all the args in sysInfo in one print statement
Number of processors: 16,
Page size: 4096 bytes,
Processor type: 8664,
Allocation granularity: 65536 bytes,
Minimum application address: 0x10000,
Maximum application address: 0x7ffffffeffff
Active processor mask: 65535,
Processor architecture: 9,
Processor level: 25,
Processor revision: 20480
Windows的字符串
咱们正常的C语言编程中,至少是不用咋太关心字符串的编码风格问题(最一般的情况),但是,Windows API在当初的时候,是划分出来两个大阵营的API,一类是A尾缀的API,也就是说,这个API设计的参数是ASCII字符串就能搞定的。那另一个是W,这是什么呢?答案是宽字符串,其是兼容咱们的Unicode字符串的
- UTF-8 - 网页常用的编码方式。这种编码方式对 ASCII 码中的拉丁字符使用一个字节,而对其他语言(例如中文、希伯来语、阿拉伯语等)的每个字符使用更多字节。这种编码方式之所以流行,是因为如果文本主要为英文,则其大小会更紧凑。通常,UTF-8 每个字符使用 1 到 4 个字节。
- UTF-16 - 在大多数情况下每个字符使用两个字节,并且所有语言都只用两个字节。一些中文和日文中较为生僻的字符可能需要四个字节,但这种情况很少见。
- UTF-32 - 每个字符使用四个字节。这种方式最容易使用,但可能也是最浪费空间的。
当大小很重要时,UTF-8 可能是最佳选择,但从编程的角度来看,它存在问题,因为无法使用随机访问。例如,要获取 UTF-8 字符串中的第 100 个字符,代码需要从字符串的开头扫描并按顺序执行,因为无法知道第 100 个字符可能在哪里。另一方面,UTF-16在编程中使用起来更方便(如果我们忽略那些特殊情况),因为访问第 100 个字符意味着在字符串的起始地址上添加 200 个字节。UTF-32 太浪费了,很少使用。幸运的是,Windows 在其内核中使用 UTF-16,其中每个字符恰好占 2 个字节。
Windows API 也遵循这一原则,使用 UTF-16 编码,这非常好,因为当 API 调用最终进入内核时,字符串不需要进行转换。然而,Windows API 存在一些小问题。部分 Windows API 是从 16 位 Windows 和消费级 Windows 系统(Windows 95/98)迁移而来的。这些系统主要使用 ASCII 编码,这意味着Windows API 使用的是 ASCII 字符串,而不是 UTF-16。当引入双字节编码时,问题变得更加复杂,因为每个字符占用一到两个字节,这失去了随机访问的优势。
所有这些最终导致 Windows API 出于兼容性考虑,同时包含 UTF-16 和 ASCII 函数。由于上述系统如今已不复存在,因此最好不要使用每个字符占用一个字节的字符串,而只使用 UTF-16 函数。对于我们今天的系统而言,使用 ASCII 函数会导致字符串被转换为 UTF-16 编码,然后才能使用 UTF-16 函数。
但是不管怎么说,我们现在看到的API的确是被遗产所影响的,为此,微软也提供了一个新的抽象:
typedef LPCSTR LPCTSTR; // const char* (UNICODE not defined)
typedef LPCWSTR LPCTSTR; // const wchar_t* (UNICODE defined)
这里的意思是说,LPCTSTR是一个非常灵活的字符串类型,如果我们在使用UNICODE环境(也就是UNICODE宏被定义的情况下),咱们的LPCTSTR默认就是LPCWSTR,反之就是普通的ASCII字符串。
我们刚刚说过WindowsAPI因此分成了两个大部分。为了让我们的程序具备通用性,微软建议我们这样类似的书写API
CreateMutex(NULL, FALSE, TEXT("CharliesMutex"));
以CreateMutex为例子,如果你把鼠标指向这里,你会发现实际上他是一个包装起来的宏,它会根据咱们是否为UNICODE环境选择不一样的实现,
那下面这个TEXT又是什么呢?答案是:
#ifdef UNICODE // r_winnt
#ifndef _TCHAR_DEFINED
typedef WCHAR TCHAR, *PTCHAR;
typedef WCHAR TBYTE , *PTBYTE ;
#define _TCHAR_DEFINED
#endif /* !_TCHAR_DEFINED */
typedef LPWCH LPTCH, PTCH;
typedef LPCWCH LPCTCH, PCTCH;
typedef LPWSTR PTSTR, LPTSTR;
typedef LPCWSTR PCTSTR, LPCTSTR;
typedef LPUWSTR PUTSTR, LPUTSTR;
typedef LPCUWSTR PCUTSTR, LPCUTSTR;
typedef LPWSTR LP;
typedef PZZWSTR PZZTSTR;
typedef PCZZWSTR PCZZTSTR;
typedef PUZZWSTR PUZZTSTR;
typedef PCUZZWSTR PCUZZTSTR;
typedef PZPWSTR PZPTSTR;
typedef PNZWCH PNZTCH;
typedef PCNZWCH PCNZTCH;
typedef PUNZWCH PUNZTCH;
typedef PCUNZWCH PCUNZTCH;
#define __TEXT(quote) L##quote // r_winnt
#else /* UNICODE */ // r_winnt
#ifndef _TCHAR_DEFINED
typedef char TCHAR, *PTCHAR;
typedef unsigned char TBYTE , *PTBYTE ;
#define _TCHAR_DEFINED
#endif /* !_TCHAR_DEFINED */
typedef LPCH LPTCH, PTCH;
typedef LPCCH LPCTCH, PCTCH;
typedef LPSTR PTSTR, LPTSTR, PUTSTR, LPUTSTR;
typedef LPCSTR PCTSTR, LPCTSTR, PCUTSTR, LPCUTSTR;
typedef PZZSTR PZZTSTR, PUZZTSTR;
typedef PCZZSTR PCZZTSTR, PCUZZTSTR;
typedef PZPSTR PZPTSTR;
typedef PNZCH PNZTCH, PUNZTCH;
typedef PCNZCH PCNZTCH, PCUNZTCH;
#define __TEXT(quote) quote // r_winnt
#endif /* UNICODE */ // r_winnt
#define TEXT(quote) __TEXT(quote) // r_winnt
非常长,但是实际上我们仔细瞧瞧就会发现他不过是决定我们字符串的字面量是不是长字符串。
const char name1[] = "Hello"; // 6 bytes (including NULL terminator)
const wchar_t name2[] = L"Hello"; // 12 bytes (including UTF-16 NULL terminator)
这就是比较糙的点了,长字符串必须要求带有L前缀修饰,不可以自动被转换。所以,如果我们不加TEXT修饰符的话,一旦我们更改环境就会导致严重的编译不通过灾难,我们不得不为所有的字面量添加L(太地狱了!)
C/C++ 运行时中的字符串
C/C++ 运行时有两组用于操作字符串的函数。经典的 (ASCII) 函数以“str”开头,例如 strlen、strcpy、strcat 等;Unicode 函数以“wcs”开头,例如 wcslen、wcscpy、wcscat 等。
与 Windows API 类似,有一组宏会根据另一个编译常量 _UNICODE(注意下划线)扩展为 ASCII 或 Unicode 版本。这些函数的前缀是“_tcs”。因此,我们有名为 _tcslen、_tcscpy、_tcscat 等的函数,它们都使用 TCHAR 类型。
Visual Studio 默认定义了 _UNICODE 常量,因此如果使用“_tcs”函数,我们得到的是 Unicode 函数。如果只定义一个“UNICODE”常量,会非常奇怪,所以请避免这种情况。
需要注意的是,我们往往还会出现需要接受字符串参数的情况。这种呢,咱们要分为两类看。
一种是类似于的GetSystemDirectory,他是这样使用的。
TCHAR sysDirentFolder[MAX_PATH];
::GetSystemDirectory(sysDirentFolder, MAX_PATH);
std::print("System Directory: {}", sysDirentFolder); // 注意,如果是Unicode环境跑不通,先别着急,看下面的套一层to_utf8就好。
这种方式,你会发现是我们需要提供自己搞定的一个内存区域,自己分配开辟和释放。也就必须要提供说明:哪里是你可以写入的,你能写入多少的参数。
另外一种是FormatMessage的API
#include <Windows.h>
#include <print>
std::string to_utf8(LPCWSTR wstr)
{
if (!wstr)
return {};
int size = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, nullptr, 0, nullptr, nullptr);
std::string result(size - 1, 0); // 不包含末尾 '\0'
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, result.data(), size, nullptr, nullptr);
return result;
}
int main(int argc, char* argv[])
{
if (argc < 2) {
std::print("Error: <exe> <error_number> to see format message");
return -1;
}
int err_num = 0;
try {
err_num = std::atoi(argv[1]);
} catch (...) {
std::print("Can not transform {} to a number", argv[1]);
return -1;
}
LPTSTR text;
auto result = FormatMessage(
FORMAT_MESSAGE_ALLOCATE_BUFFER | // function allocates
FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_IGNORE_INSERTS,
nullptr, err_num, 0,
(LPTSTR)&text, // ugly cast
0, nullptr);
if (result > 0) {
std::println("code <{}> formatted: {}", err_num, to_utf8(text));
::LocalFree(text);
} else {
std::println("Can not parse the code <{}> for formated message!", err_num);
}
return 0;
}
to_utf8是一个这样的API,他只是做简单的转换,将我们拿到的宽字符转成多字节的可以兼容C++标准的输出。
回归正题,FormatMessage中指定了FORMAT_MESSAGE_ALLOCATE_BUFFER的时候,咱们实际上就是让text来决定我们的buffer到底指向何方,但实际上这个行为是很不安全的(编译器甚至给我送了一个警告)
Windows API的错误码
| 返回类型 | 成功返回值 | 失败返回值 | 如何获取错误码 |
|---|---|---|---|
| BOOL | 非 FALSE(通常为 TRUE / 1) | FALSE(0) | 调用 GetLastError() |
| HANDLE | 非 NULL 且不等于 INVALID_HANDLE_VALUE | NULL 或 INVALID_HANDLE_VALUE (-1) | 调用 GetLastError() |
| void | 无(通常不会失败) | 无(少数情况会抛 SEH 异常) | 通常不需要,但异常情况下查文档 |
| LSTATUS / LONG | ERROR_SUCCESS(0) | 大于 0 的值表示错误码 | 返回值本身就是错误码 |
| HRESULT | 大于或等于 0,通常为 S_OK(0) | 负数表示错误码 | 返回值本身就是错误码 |
| 其他类型 | 根据函数文档 | 根据函数文档 | 查具体函数文档 |
错误处理我想我们都很熟悉,这里是Windows的错误处理决定的。


